Ollama supports advanced multimodal models that can process both text and images. This guide will show you how to download a multimodal model, run it, and use it for image captioning and contextual conversations—all locally on your machine.
Step 1 : Choose and Download a Multimodal Model
Multimodal models can handle images in addition to text. A popular example is llava. Visit the Ollama model library and find a suitable multimodal model, such as llava:7b.
To download the model, run:
Downloading may take some time depending on your internet speed and the model size.
Step 2 : Prepare Your Image
Make sure you have an image file available on your computer that you want to use for captioning.
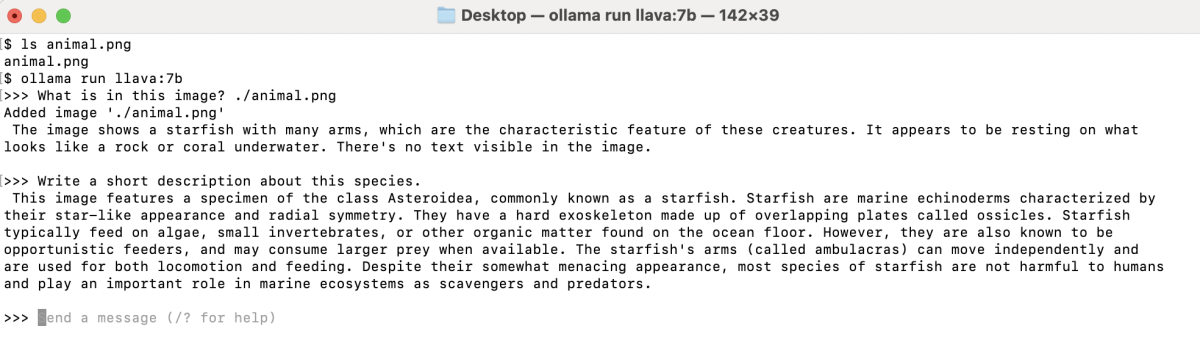
In this example, we'll use a photo of a starfish, saved as animal.png.

Step 3 : Start the Multimodal Model
Begin an interactive session with the model:

Step 4 : Caption an Image
To get a description of your image, type the following at the Ollama prompt:

The model will analyze the image and respond with a detailed caption, for example:
The image shows a starfish with many arms, which are the characteristic feature of these creatures. It appears to be resting on what looks like a rock or coral underwater. There's no text visible in the image.
Step 5 : Ask Follow-up and Contextual Questions
You can further interact with the model about the image. Try asking:
- "Write a short description about this species."
- "Where does this species live?"

- "What is the average lifespan of this species?"

The model will use the context of the previous image and its own responses to keep the conversation relevant.
- All processing happens locally; your images and data are not sent to any external server.
- Context is preserved within your session, so follow-up questions remain relevant to the image you provided.
Step 6 : End the Session
When you are done, type /bye or press Ctrl+D to exit the chat session.
With Ollama and multimodal models, advanced image captioning and context-rich AI conversations are right at your fingertips—no cloud required!