Retrieval-Augmented Generation (RAG) enables your LLM-powered assistant to answer questions using up-to-date and domain-specific knowledge from your own files. This guide will show you how to build a complete, local RAG pipeline with Ollama (for LLM and embeddings) and LangChain (for orchestration)—step by step, using a real PDF, and add a simple UI with Streamlit.
What is RAG and Why Use It?
Language models are powerful, but limited to their training data. RAG (Retrieval-Augmented Generation) connects an LLM with a retriever that searches your own documents, making it possible to answer questions grounded in real, current, and private knowledge.
How RAG works:
- Your documents are split into chunks and converted to embeddings (vectors).
- Both the embeddings and the original text are stored in a vector database.
- Your query is also embedded and used to retrieve similar chunks.
- The LLM generates an answer using both your query and the retrieved content.
RAG reduces hallucinations and makes your assistant far more useful for practical, real-world scenarios.
Core Concepts
- Document Loading & Chunking: Load sources (PDFs, text, URLs) and split into smaller pieces.
- Embeddings: Each chunk is transformed into a vector using an embedding model; similar content produces similar vectors.
- Vector Database: Both vectors and original text are stored in a special database (e.g., ChromaDB).
- Retrieval: When you query, your question is embedded and the database finds the most relevant chunks. These are passed to the LLM for a grounded answer.
Setup
- Folder structure:
- Create a virtual environment
- Activate the environment
On macOS/Linux:
On Windows:
- requirements.txt
Install dependencies:
RAG Pipeline Example
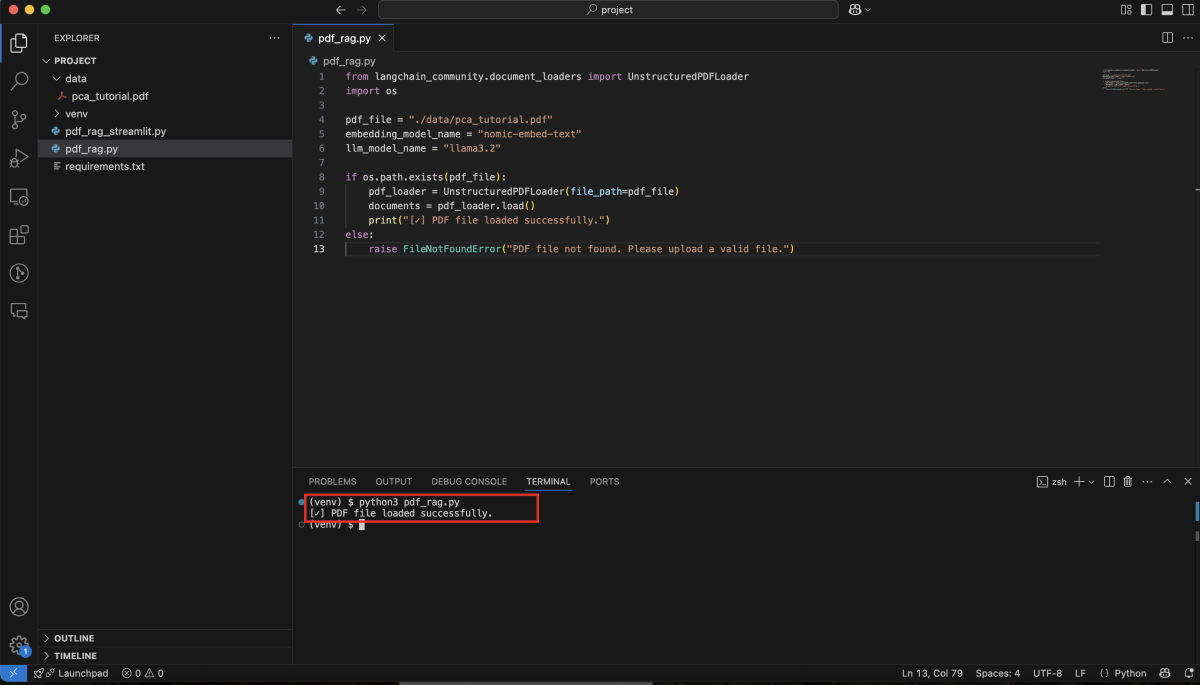
Step 1 : Load and Ingest a PDF
We start by loading a PDF file. You can either upload one or use a local path:
Step 2 : Split the PDF into Chunks
To make the document searchable, we need to chunk it into smaller parts.
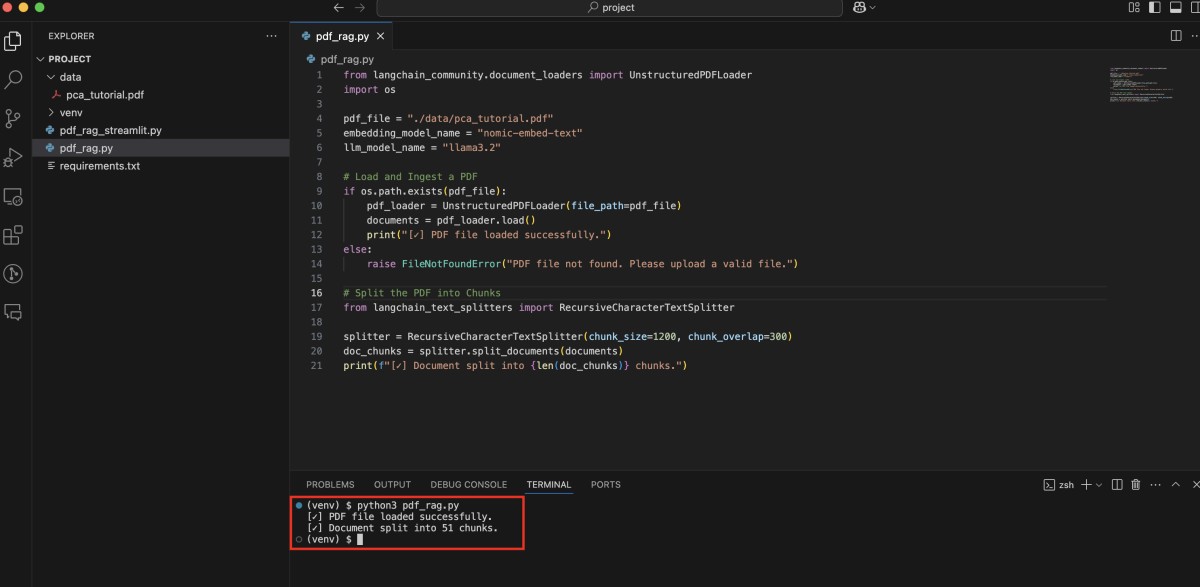
Step 3 : Embed Chunks into Vector Database
We'll use the nomic-embed-text embedding model via Ollama, and store everything in ChromaDB:
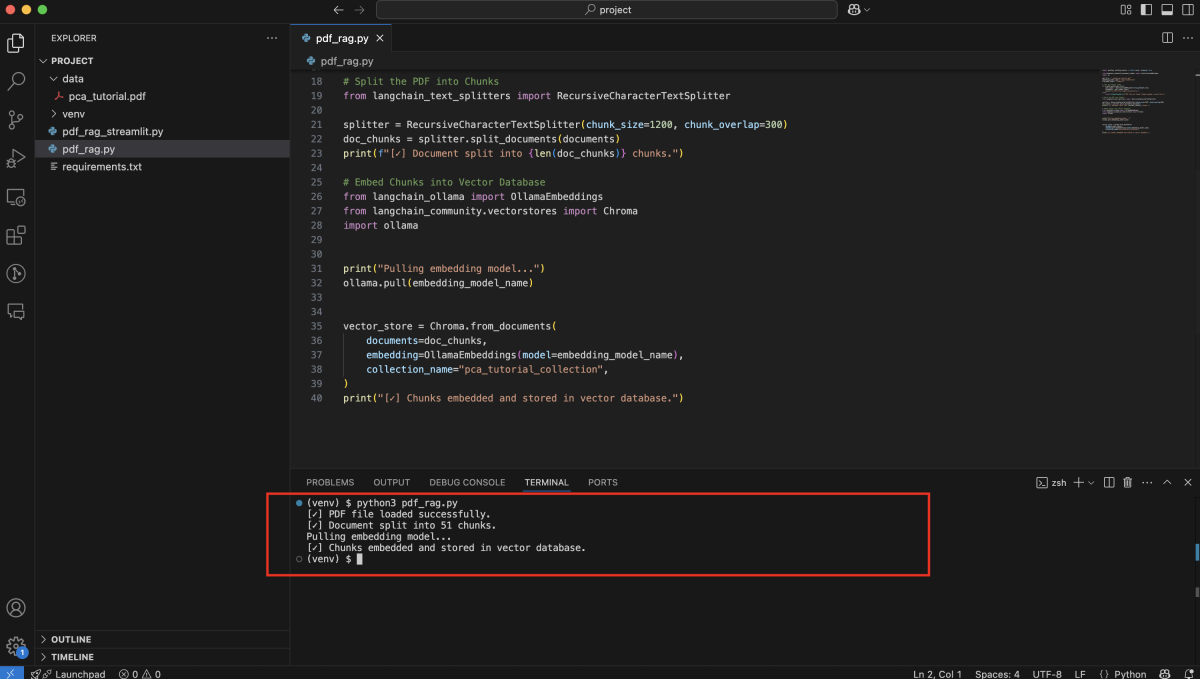
Step 4 : Setup the Retriever with Multi-Query
To improve retrieval quality, we generate multiple variations of the input question using an LLM:
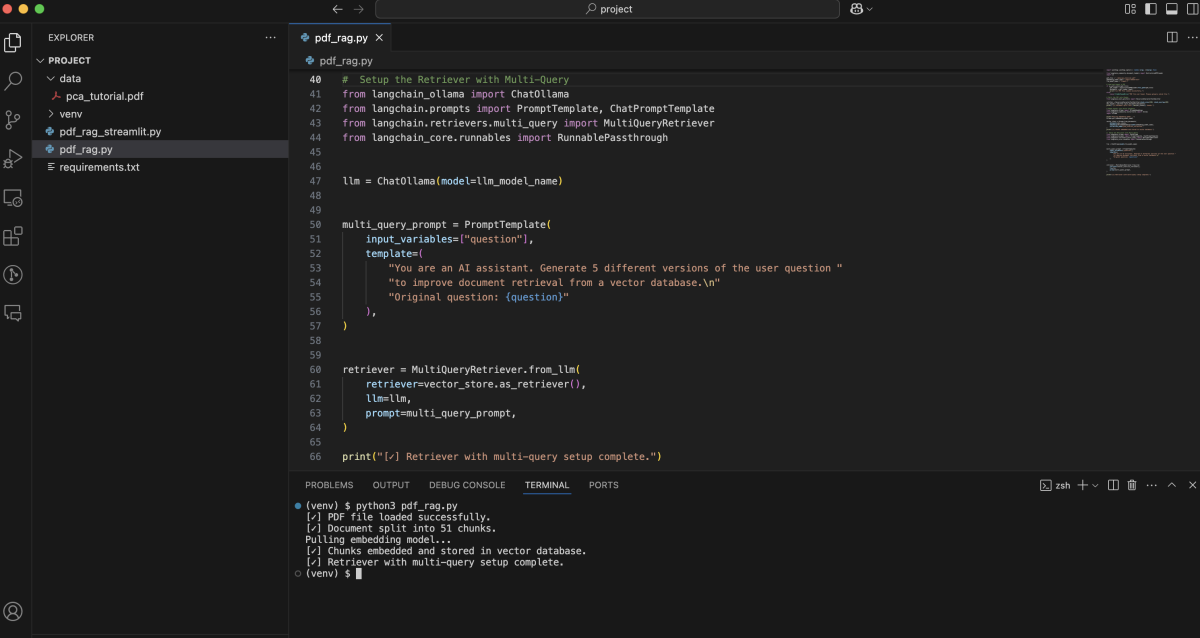
Step 5 : Ask Questions with RAG Pipeline
Let's define the full chain that combines retrieval + prompt + LLM:
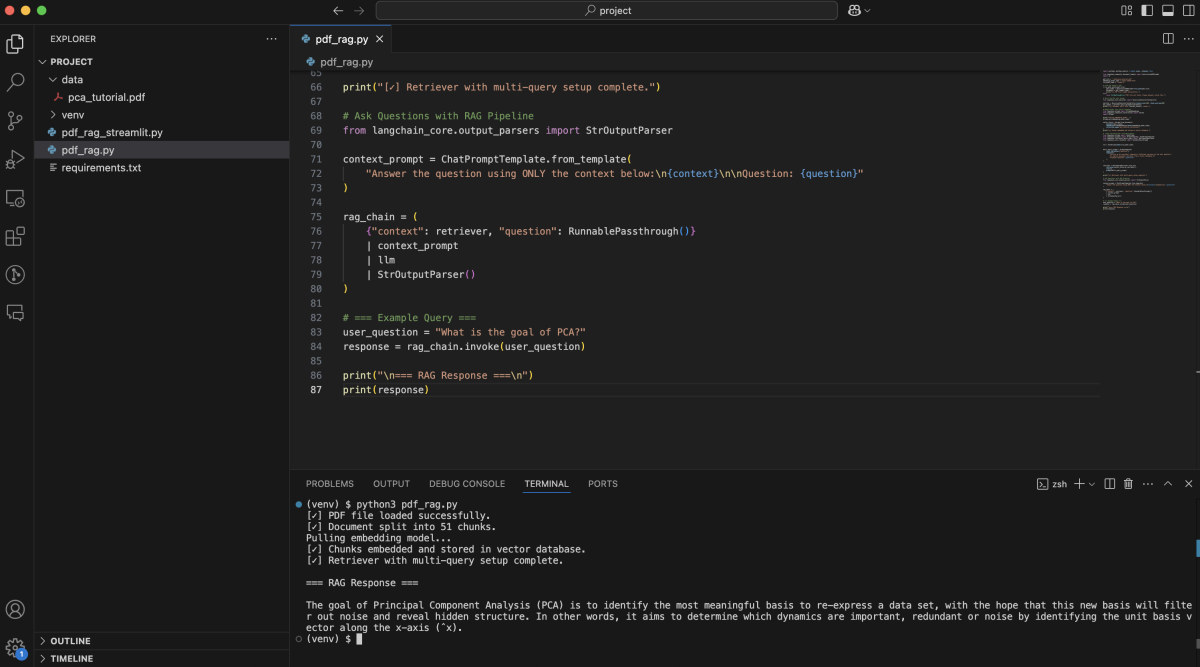
Step 6 : Full Source Code
Here's the complete script you can run end-to-end:
Run with Streamlit UI
To make your RAG pipeline interactive, let's wrap it in a simple Streamlit app. Here's how to get started:
Step 7 : Install Streamlit
Add streamlit to your requirements.txt if not already included:
Or install it directly:
Step 8 : Create a Streamlit App
Save the following code as pdf_rag_streamlit.py:
Step 9 : Launch the App
Visit http://localhost:8501 to interact with your PDF using natural language.

And enter your question into the input box to get answers based on the PDF content.

You'll get a clean UI in your browser where you can type questions and receive answers based on the content of your PDF.