If you want to experiment, research, or develop apps with Large Language Models (LLMs) directly on your own computer—no API fees, no data privacy concerns—Ollama is the answer. This open-source tool lets you download, run, and manage a variety of LLMs (like Llama, Mistral, etc.) quickly and easily, right on Windows, macOS, or Linux.
What is Ollama? Key Advantages
- Ollama is an open-source tool that lets you:
- Download, manage, and switch between multiple LLMs.
- Run models entirely on your local machine (no cloud, no data sent out).
- Get started easily—no deep ML/AI know-how required.
- Save money (no API fees, no usage limits).
- Stay private: all data stays on your device.
- Supports Windows, macOS, and Linux.
System Requirements
- OS: Windows, macOS, or Linux (recent versions)
- Free storage: minimum 10GB (models can be very large)
- CPU: any modern processor (recent laptops/desktops are fine; GPU is a plus)
- Python: Only needed if you want to use Python APIs.
- Code editor: VSCode, PyCharm, or your preferred editor.
Installing Ollama
Download & Install
1. Go to ollama.com.
2. Click Download—the site will auto-detect your OS and suggest the correct installer.
- macOS/Windows: Download the .dmg or .exe, open and install as usual.
- Linux: Copy the install command from the site and run it in your terminal.
3. On macOS, move Ollama to Applications and grant permissions if asked.
4. Some models are very large (2GB–30GB+). Double-check your free disk space.
5. If you prefer command line: install the Ollama CLI for direct terminal control.
Running Your First LLM
After installing Ollama:
- On Windows/macOS: Open the Ollama app and follow prompts to install the CLI/tool.
- On terminal (all OS): Run the following command to download and start Llama 3 (as an example):
The first run will automatically download the model (may take several minutes).
When finished, you'll see a chat interface—type questions to interact with the AI locally.
Then, in the shell:

Ollama will return the answer instantly from Llama 3.2. To exit, type:

Managing Multiple Models with Ollama
Browse and Download Other Models
Open the Models tab in the Ollama app or visit ollama.com/library to see a list of featured, new, or popular models.
Each model often has several “flavors” (variants), for example:
- llama3.2:1b: Lightweight, fast, uses less RAM (~1.3GB).
- llama3.2:3b: Larger, more capable, uses more RAM and disk.
Choose the variant that matches your hardware and needs.
Download and Switch Models
For example, to download and run the smaller Llama 3.2 1B variant:
To list all models you have downloaded:

Remove Models You Don't Need

Understanding Model Parameters
When you run /show info in the model shell, you'll see fields like:
- Architecture: Llama/Mistral/etc.—the model type.
- Parameters (B): Number of model parameters (billions). Bigger = smarter, but needs more resources.
- Context length: Max tokens per prompt (larger is better for long docs).
- Embedding length: Vector size for tokens (higher = better semantic understanding).
- Quantization: Compression method (e.g., 4-bit) to reduce size and increase speed.

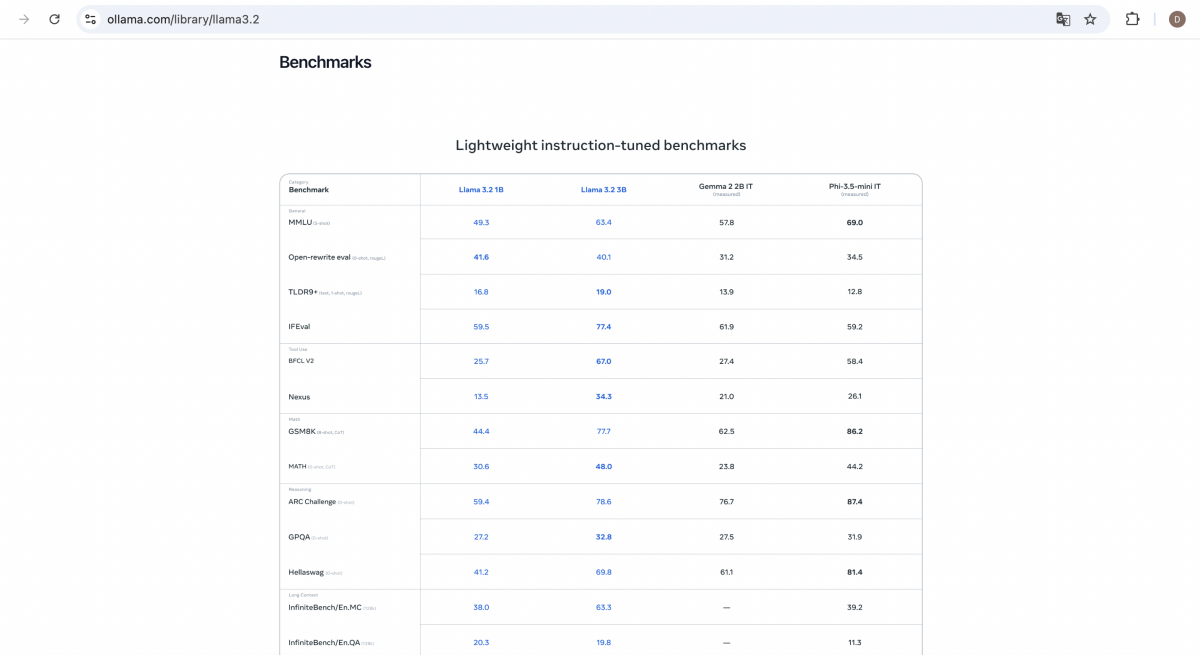
Benchmarks & Choosing the Right Model
- Check the model's benchmark table for strengths (summarization, rewriting, multi-language, etc.).
- Don't trust benchmarks blindly—always test with your real use case.
- For personal computers, 1B–8B models are most practical. 70B–405B only suit high-end workstations/servers with a lot of RAM.
Ollama is well-suited for learning, research, and building privacy-first applications with LLMs. By experimenting with different models and flavors, you can find the best fit for your specific needs and hardware. Regularly removing unused models helps manage disk space efficiently.